Podcastfy
综合介绍
Podcastfy 是一个开源的 Python 工具包,它可以利用生成式人工智能(GenAI)技术,将多种来源和格式的内容,例如网站文章、PDF文档、YouTube视频甚至图片,转换成引人入胜的、支持多种语言的音频对话。这个项目可以看作是谷歌 NotebookLM 产品中播客功能的开源替代品,但 Podcastfy 更专注于通过编程方式进行定制化和规模化的内容生成。用户不仅可以调用 OpenAI、Anthropic、Google 等主流厂商的先进大语言模型和语音生成模型,还可以选择在本地运行超过156种 HuggingFace 上的开源模型,从而在保护数据隐私的同时,对生成的内容有更强的控制力。无论是内容创作者希望将博客文章转换成播客,还是教育工作者希望将课程材料制作成音频,Podcastfy 都提供了一个灵活且强大的解决方案。
功能列表
- 多模态内容输入: 支持从网站链接、PDF文档、YouTube视频、图片以及用户自定义主题等多种来源获取内容。
- 播客形式多样: 可生成2到5分钟的简短播客,也支持生成30分钟以上的长篇播客。
- 高度定制化: 用户可以自定义对话脚本的风格、语言和结构,以及选择不同的声音。
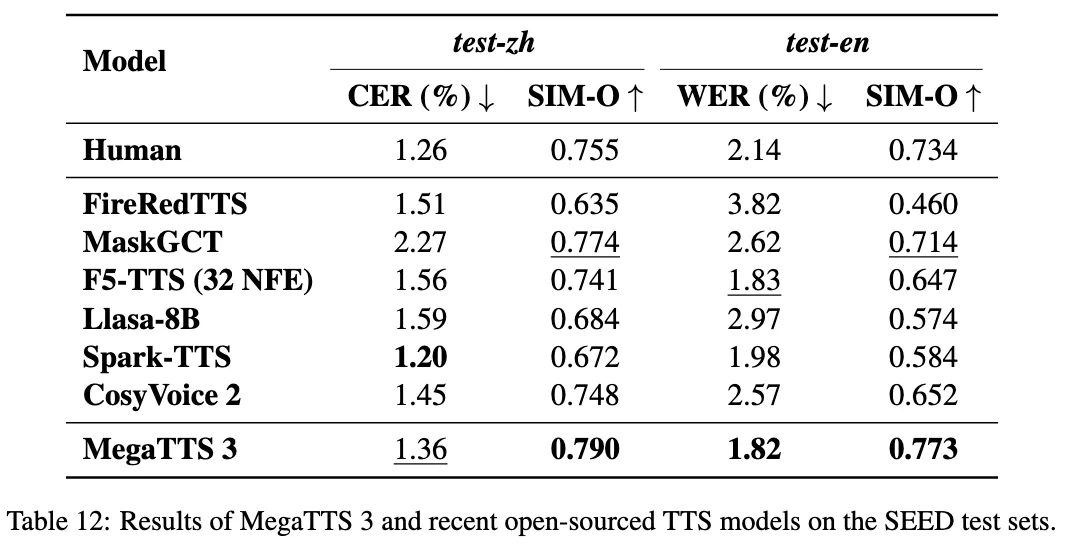
- 广泛的模型支持: 脚本生成环节集成了超过100种大语言模型(LLM),包括OpenAI、Anthropic、Google的模型。
- 本地模型部署: 支持在本地运行超过156种HuggingFace上的开源大语言模型,保障数据隐私。
- 先进的语音合成: 集成了OpenAI、Google、ElevenLabs和Microsoft Edge等多种先进的文本转语音(TTS)模型。
- 多语言支持: 能够生成多种语言的音频内容,满足全球化内容创作的需求。
- 便捷的集成方式: 提供命令行工具(CLI)和Python库两种方式,方便集成到自动化工作流程中。
- 实时网络搜索: 可以根据用户输入的主题,结合实时的网络搜索结果生成有事实依据的播客内容。
使用帮助
Podcastfy 提供了多种使用方式,包括 Python 库、命令行工具(CLI)以及一个基于 FastApi 的 Web 应用接口。以下将详细介绍如何安装和使用这些功能。
前期准备
在开始使用之前,你需要确保电脑上已经安装了以下软件:
- Python: 版本要求为 3.11 或更高。
- FFmpeg: 这是一个处理音视频文件的开源工具,Podcastfy 需要用它来处理音频。你需要先安装它,并确保其在系统的环境变量中可以被调用。
安装 Podcastfy
安装过程非常简单,只需要一个命令即可。打开你的终端或命令行工具,输入以下命令:
pip install podcastfy
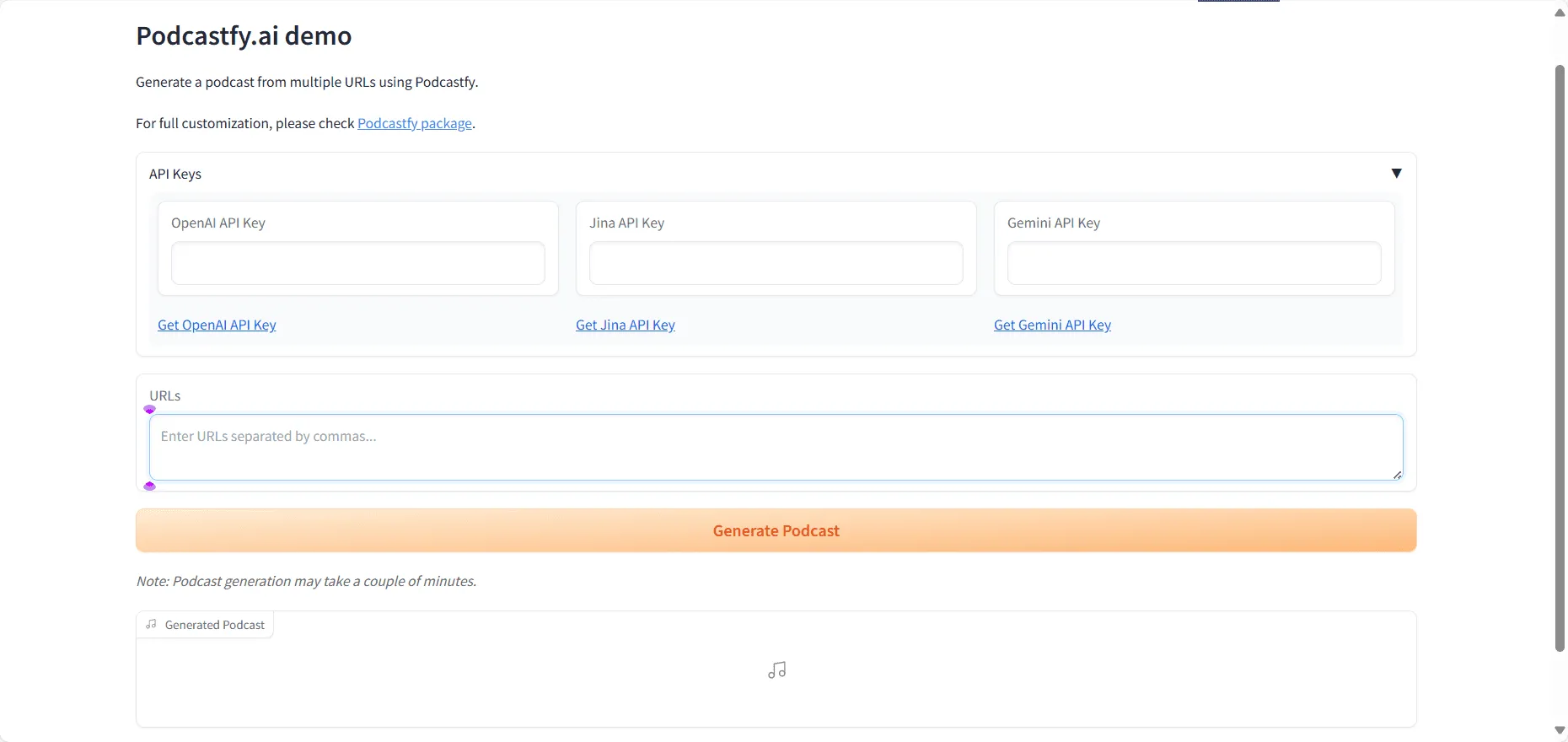
设置 API 密钥
Podcastfy 需要调用第三方AI模型的API,所以你需要准备好相应平台的API密钥。例如,如果你想使用 OpenAI 的 GPT-4o 和 TTS 模型,你需要先获取 OpenAI 的 API 密钥。
在你的Python项目中,你可以通过以下方式设置密钥:
import os
# 将你的密钥设置为环境变量
os.environ["OPENAI_API_KEY"] = "sk-xxxxxxxxxxxxxxxxxxxxxxxxx"
# 如果使用ElevenLabs,也需要设置相应的密钥
# os.environ["ELEVEN_LABS_API_KEY"] = "el-xxxxxxxxxxxxxxxxxxxxxxxxx"
核心功能操作:生成播客
1. 使用 Python 库
这是最灵活也是最常用的方式。你可以轻松地在自己的Python代码中集成Podcastfy。
基础用法:根据URL生成播客
假设你想把几篇网页文章转换成一段播客,可以这样做:
from podcastfy.client import generate_podcast
# 定义一个包含多个网址的列表
urls_to_podcast = [
"https://example.com/article1",
"https://example.com/article2"
]
# 调用核心函数生成播客
# 函数会返回生成的音频文件路径
audio_file_path = generate_podcast(urls=urls_to_podcast)
print(f"播客已生成,文件路径: {audio_file_path}")
````generate_podcast` 函数会自动抓取网页内容,生成对话脚本,并合成为音频文件。
**进阶用法:自定义播客内容**
你可以对生成的播客进行详细的定制,例如对话风格、发言人数量、使用的AI模型等。
```python
from podcastfy.client import generate_podcast
from podcastfy.config import Config, OpenAITextToSpeechModels, OpenAILLMModels
# 创建一个自定义配置对象
custom_config = Config(
llm_model=OpenAILLMModels.GPT_4_O, # 使用GPT-4o模型生成脚本
tts_model=OpenAITextToSpeechModels.TTS_1_HD, # 使用高质量的TTS模型
podcast_format="interview", # 设置播客形式为访谈
podcast_speakers=3, # 设置三位发言人
language="Chinese", # 生成中文播客
long_form=False # 生成一个短播客 (2-5分钟)
)
# 根据自定义配置和URL生成播客
audio_file_path = generate_podcast(
urls=["https://www.some-chinese-website.com/news"],
config=custom_config
)
print(f"中文访谈播客已生成: {audio_file_path}")
2. 使用命令行工具 (CLI)
如果你不希望编写代码,或者想快速地在终端里生成播客,可以使用命令行工具。
基础用法:打开终端,输入以下命令,并将 <url1> 替换为实际的网址。
python -m podcastfy.client --url <url1> --url <url2>
程序运行结束后,会在当前目录下生成一个音频文件。
进阶用法:命令行工具同样支持丰富的参数来自定义播客。例如,你可以指定语言和话题。
python -m podcastfy.client --topic "The history of Artificial Intelligence" --language "English"
这个命令会让Podcastfy围绕“人工智能的历史”这个主题,通过实时网络搜索来收集资料,并生成一段英文播客。
3. 使用 FastApi 接口 (Beta)
对于希望将Podcastfy部署为网络服务的开发者,项目提供了一个基于FastApi的实现。你可以将其容器化并部署。
部署步骤:
- 克隆项目:
git clone https://github.com/souzatharsis/podcastfy.git - 进入目录:
cd podcastfy - 使用 Docker 构建并运行:
docker build -t podcastfy-api -f Dockerfile_api . docker run -p 8000:8000 podcastfy-api
服务启动后,你就可以通过向 http://localhost:8000/generate_audio/ 端点发送POST请求来生成播客。请求的body需要包含URL列表等信息,具体可以参考项目中的 podcastfy.ipynb 笔记本文件获取请求示例。
应用场景
- 内容创作者内容创作者可以将自己发布的博客文章、深度报道或研究成果,通过Podcastfy快速转换成音频格式的播客。这不仅能将内容触达给那些喜欢听觉消费的受众,还能将同样的内容发布到Spotify、Apple Podcasts等音频平台,扩大影响力。
- 教育工作者与学生教师可以将课程讲义、学术论文、甚至包含图表的复杂教材转换成易于理解的对话式音频。这为有视觉障碍或阅读障碍的学生提供了极大的便利,也让所有学生都能在通勤或运动时,通过“听”的方式来复习和学习。
- 研究人员科研人员可以将冗长且充满专业术语的研究论文或技术文档,生成为一段访谈式的音频摘要。这有助于他们向非专业领域的同行、投资人或公众更清晰地解释自己的研究成果,促进跨学科交流和知识传播。
- 数字无障碍倡导者对于致力于推动信息无障碍的个人和组织,Podcastfy是一个强大的工具。它可以将互联网上大量的视觉和文本内容转换成听觉内容,帮助那些因视力障碍、阅读障碍或其他残疾而难以访问标准网络内容的用户,平等地获取信息。
QA
- Podcastfy支持哪些语言?Podcastfy支持其集成的文本转语音(TTS)模型所支持的所有语言。由于集成了Google、OpenAI等多种领先的TTS服务,它能够支持全球多种主流语言,包括中文、英文、西班牙语、法语等。用户可以在配置中通过
language参数指定生成播客的语言。 - 使用Podcastfy是否需要付费?Podcastfy本身是一个开源项目,使用其代码是免费的。但是,它依赖于第三方的大语言模型(LLM)和文本转语音(TTS)服务,例如OpenAI API、Google AI Platform API等。调用这些API通常需要根据使用量支付费用。如果你想完全免费使用,可以选择配置本地运行的开源LLM模型。
- 我能否使用自己的声音来生成播客?目前Podcastfy的官方版本还不直接支持声音克隆功能。但是,它集成的某些TTS服务(如ElevenLabs)提供了声音克隆的API。有编程能力的用户可以尝试修改代码,将自己的声音通过这些服务集成到播客生成流程中。
- 生成一个30分钟的长播客大概需要多长时间?生成时间取决于多个因素,包括输入内容的复杂程度、选择的LLM模型的响应速度、以及TTS模型的处理速度。通常,生成对话脚本是最耗时的步骤。一个30分钟的长播客,从内容处理到最终音频生成,可能需要几分钟到十几分钟不等。